Многие NoSQL базы данных, в основе которых лежат концепции Google BigTable, в качестве формата файла для хранения данных на диске используют SSTable. К таким базам можно отнести, например, Cassandra, HBase и LevelDB. Однако, не смотря на обилие информации об этих хранилищах, мало кто задается вопросом, почему именно SSTable? Именно на этот вопрос я и постараюсь дать развернутый ответ.
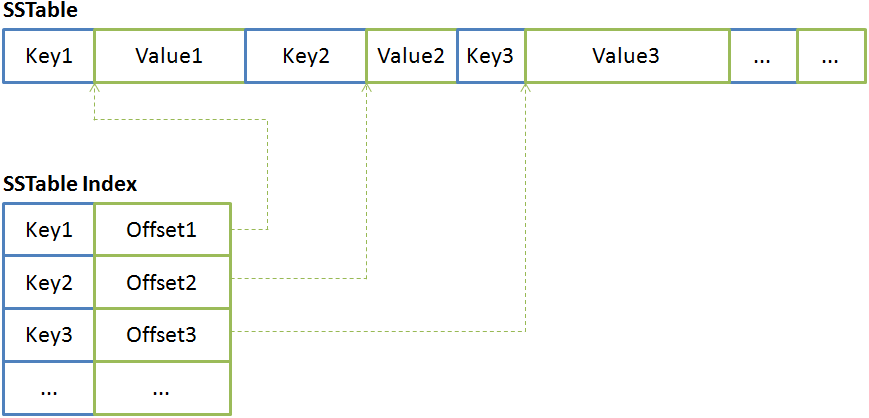
SSTable (Sorted String Table) – простой формат для эффективного хранения большого числа пар типа “ключ-значение”, оптимизирован для обеспечения высокой пропускной способности при выполнении операций последовательного чтения и записи данных. В связи с этим данный формат позволяет достаточно просто обрабатывать большие объемы информации, амортизируя нагрузку на диск. Формат не предъявляет никаких требований к размеру “ключей” и “значений”, но предполагает, что все ключи отсортированы. Таким образом, осуществляя последовательное чтение, можно получить отсортированный индекс, который будет содержать смещения до соответствующих “значений”, что обеспечит быстрый доступ к данным по ключу. Можно сказать, что SSTable – одновременно очень простой и очень удобный способ для работы с большими отсортированными сегментами данных.
Недостатки SSTable
Основное достоинство SSTable – в его простоте, однако у этого формата есть один недостаток. Как только SSTable оказывается на диске, он становится неэффективен в использовании. Поскольку SSTable хранит отсортированные сегменты данных, то любая операция вставки или удаления потребует больших накладных расходов из-за необходимости перезаписи всего файла. Таким образом, SSTable идеально подходит для хранения статических индексов, так как для чтения из индекса нужно всего лишь один раз позиционировать головку жесткого диска, после чего будет осуществлено последовательное чтение. Случайное чтение осуществляется также быстро.
Иначе говоря, когда речь заходит о случайной записи, то эта операция оказывается слишком долгой и дорогой, особенно, если таблица находится не в оперативной памяти. Именно по этой причине файлы SSTable, находящиеся на диске, не подлежат изменению.
Несмотря на это, данный формат оказался слишком хорош, чтобы от него отказаться, поэтому при реализации BigTable попытались решить проблему обеспечения быстрого чтения и записи при работе с SSTable. И вот, что получилось.
The Log-Structured Merge-Tree
Если присмотреться, то у нас есть все необходимые части для решения этой проблемы: случайная запись осуществляется быстро, если SSTable находится в памяти (назовем ее MemTable); чтение осуществляется также быстро, если SSTable не изменяется и находится на диске. Таким образом, если принять следующие соглашения, то можно решить обозначенную проблему:
- Индексы SSTable с диска загружаются в оперативную память
- Данные записываются непосредственно в индекс MemTable
- При чтении сначала проверяется MemTable, затем SSTable
- Периодически MemTable сбрасывается на диск в виде SSTable
- Периодически SSTable на диске объединяются в один файл
Что получаем в итоге? Запись всегда осуществляется в память, следовательно, всегда производится быстро. Как только MemTable достигает определенного размера, она сбрасывается на диск в виде неизменного SSTable. Так как все индексы SSTable находятся в памяти, при любом чтении в первую очередь проверяется MemTable, и только потом осуществляется обращение к SSTable, если данные не были найдены в MemTable.
Таким образом, мы только что заново открыли подход, который Patrick O’Neil описал в своей статье “The Log-Structured Merge-Tree” (LSM Tree)” еще в 1996 году. Этот подход и был положен в основу BigTable.
Стоит немного описать структуру ключа в BigTable. В Google BigTable двум произвольным строковым значениям (“row key” и “column key”) и временной метке (“timestamp”) в соответствие ставится произвольный массив байт. Отсюда аналогия с трехмерным отображением данных. Это не является реляционным представлением данных, наилучшим определением здесь будет: разреженное, распределенное, многомерное, отсортированное отображение. Таким образом, можно сказать, что таблица имеет несколько измерений, одно из которых – временная метка – используется для управления версиями и сборки мусора.
LSM-Tree: Update & Delete
LSM-Tree обладает рядом интересных особенностей. Вставка (insert) осуществляется всегда быстро вне зависимости от размера блока данных, случайное чтение осуществляется из памяти, либо требует обращения к диску. Но что на счет операций обновления (update) и удаления (delete)?
Файлы SSTable, находящиеся на диске, не подлежат изменению, следовательно, невозможно выполнить операции обновления и удаления данных, которые находятся в этом файле. Вместо этого в случае обновления более новые записи просто сохраняются в MemTable, а в случае удаления помечаются меткой “tombstone”. Поскольку чтение из индексов осуществляется последовательно (сначала из MemTable, затем из SSTable на диске), мы никогда не прочитаем старое значение.
Тем не менее, наличие сотней файлов SSTable на диске не очень хорошая идея. Поэтому периодически запускается процесс слияния файлов SSTable, который обновляет и удаляет записи, перезаписывая или удаляя старые данные. Этот процесс называется уплотнением (compaction).
Например, в Cassandra, чтобы ускорить операцию чтения, используются два индексных файла: индекс с указателями на данные (SSTable Index) и фильтр Блума (Bloom filter). Индекс с указателями на данные создается для каждого файла SSTable и содержит пары “ключ – смещение”, где смещение определяет расположение блока данных, ассоциированного с данным ключом и находящегося в соответствующем файле SSTable. Файл с фильтром Блума используется для минимизации обращений к жесткому диску, при проверке существования искомой записи в одном из множества SSTable. Фильтр Блума является компактной вероятностной структурой данных, которая используется для проверки принадлежности заданного элемента (ключа) множеству. При этом существует возможность получить ложноположительное срабатывание (элемента во множестве нет, но структура данных сообщает, что он есть), но не ложноотрицательное.
Заключение
Таким образом, взяв за основу формат SSTable, добавив концепцию MemTable, а также приняв соглашения, указанные выше, можно получить отличный движок базы данных, рассчитанный на определенный тип нагрузки. Под “типом нагрузки” в данном контексте понимается особенность LSM-Tree, из-за которой запись данных осуществляется быстрее чтения. Чтение данных выполняется также быстро, но медленней, чем запись, поэтому эту особенность следует учитывать при решении задач.
Таким образом, подход LSM-Tree и системы, построенные по этому принципу, наиболее применимы в приложениях, где запись данных осуществляется чаще, чем чтение. К задачам такого рода можно отнести ведение истории изменений или логирование событий.
Вышеописанный подход на данный момент используют Cassandra и Hbase, а также другие системы в различных вариациях указанной архитектуры. Но, несмотря на всю простоту, лежащую на поверхности, как обычно, детали реализации имеют огромное значение. Этими деталями и различаются NoSQL решения.
Также следует отметить, что более-менее точная копия описанной архитектуры реализована в LevelDB. Эта база представляет собой хранилище типа “ключ-значение” и используется в качестве движка для реализации IndexDB в WebKit.