С выходом Visual Studio 2010 были связаны некоторые изменения в настройках проектов C++. В частности была удалена возможность создавать собственные правила компиляции. Эти изменения внесли определенные сложности в процесс создания проектов CUDA. Далее рассматривается минимально необходимый набор действий для создания простого приложения на базе технологии CUDA в Visual Studio 2010.
Предустановки
Для полноценной разработки приложений CUDA необходимо иметь видеокарту с поддержкой данной технологии. Список поддерживаемых устройств приведен на сайте производителя. Если видеокарта поддерживает CUDA, то желательно скачать и установить последнюю версию драйвера. Даже если поддержка отсутствует, создавать CUDA-приложения возможно, просто они будут запускаться в режиме эмуляции.
Далее необходимо установить CUDA Toolkit, GPU Computing SDK и Parallel Nsight для соответствующей версии операционной системы. На момент написания данной статьи использовался пакет CUDA Toolkit 4.0 и Parallel Nsight 2.0. Названные компоненты можно скачать на официальном сайте NVIDIA. Прежде чем продолжить, следует сказать несколько слов о данных компонентах.
NVIDIA® CUDA® Toolkit – набор инструментальных средств для разработки GPU-приложений на C/C++. Эти инструменты включают: CUDA-компилятор, библиотеку математических функций, а также набор утилит для отладки и профилирования приложений. Помимо этого в поставку входит подробное описание программно-аппаратной модели, руководство пользователя и документация по CUDA API.
NVIDIA® GPU Computing SDK содержит множество примеров использования CUDA, которые сопровождаются подробным описанием.
NVIDIA® Parallel Nsight – мощное расширение для Visual Studio, позволяющее осуществлять отладку, профилирование и анализ CUDA-приложений и не только.
CUDA Toolkit 4.0 не поддерживает компилятор V100, который идет в поставке с Visual Studio 2010, поэтому для сборки CUDA-проектов нужно иметь C++ компилятор версии VC90 с соответствующим Windows SDK. Для его установки достаточно установить express - версию Visual Studio 2008 (C++).
Создание проекта
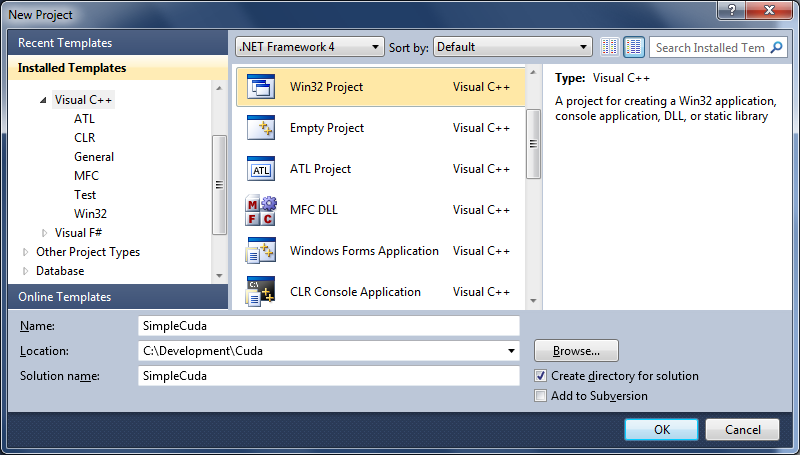
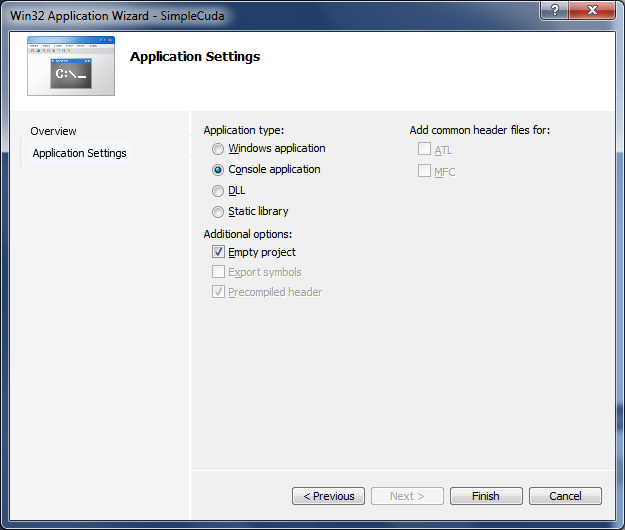
Необходимо запустить Visual Studio 2010 и создать пустой Visual C++ Win32 Project, как показано на рисунке ниже.
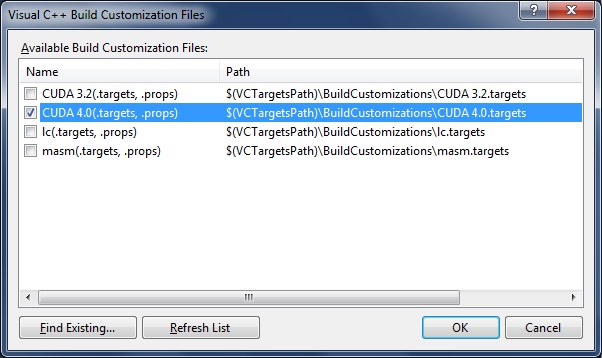
Далее следует определить правила сборки проекта. Для этого нужно вызвать меню проекта Build Customization
и поставить отметку напротив пункта CUDA 4.0. Эта настройка добавит поддержку CUDA-файлов, то есть
файлов с расширением *.cu.
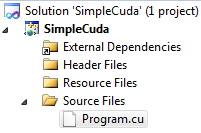
После этого в проект можно добавлять файлы с исходным кодом на CUDA. Для примера добавлен файл Program.cu.
Если CUDA-файл был добавлен не через соответствующий шаблон, а простым переименованием cpp-файла, в
свойствах нужно явно установить тип CUDA C/C++.

Далее нужно вернуться к настройкам проекта и на вкладке General установить значение свойства Platform Toolset в V90.
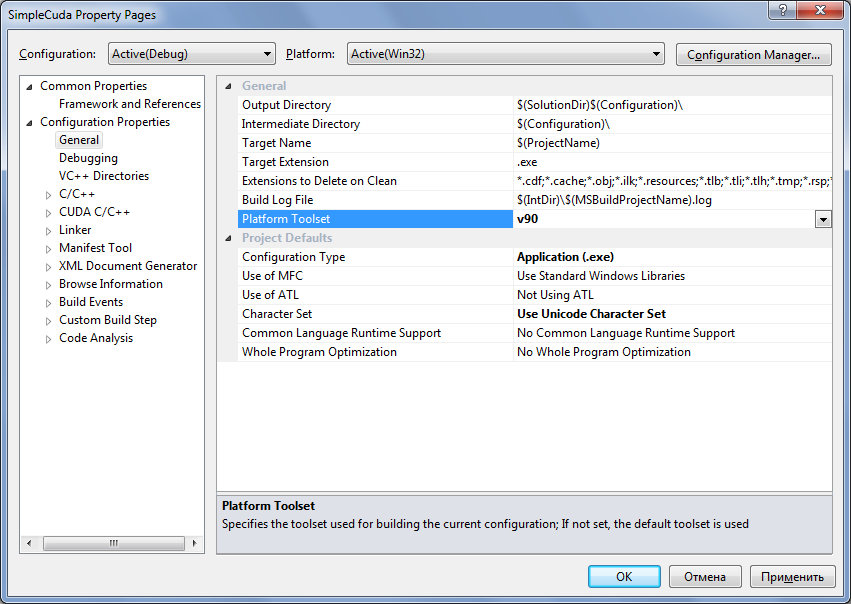
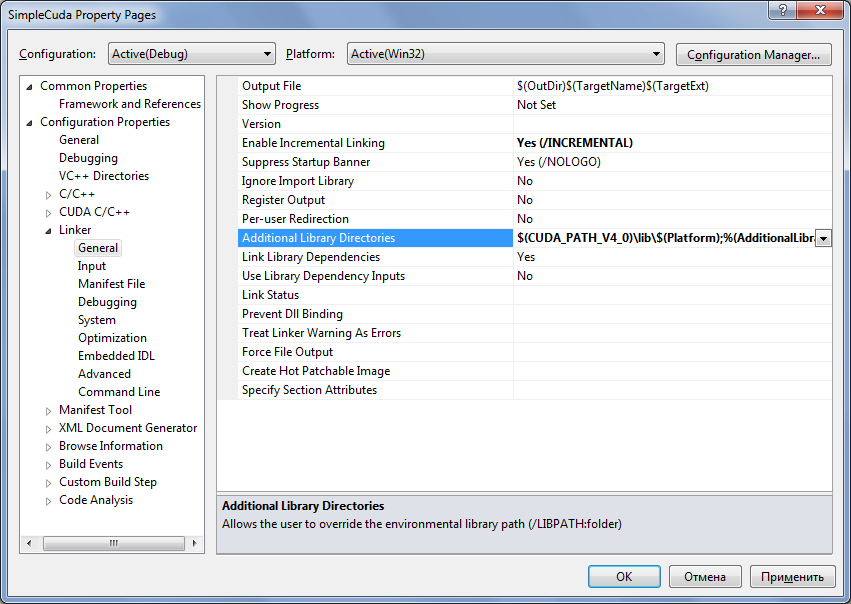
В этом же диалоге указывается путь к lib-файлам CUDA. Для этого на вкладке Linker/General в настройке
Additional Library Directories добавляется каталог $(CUDA_PATH_V4_0)\lib\$(Platform).
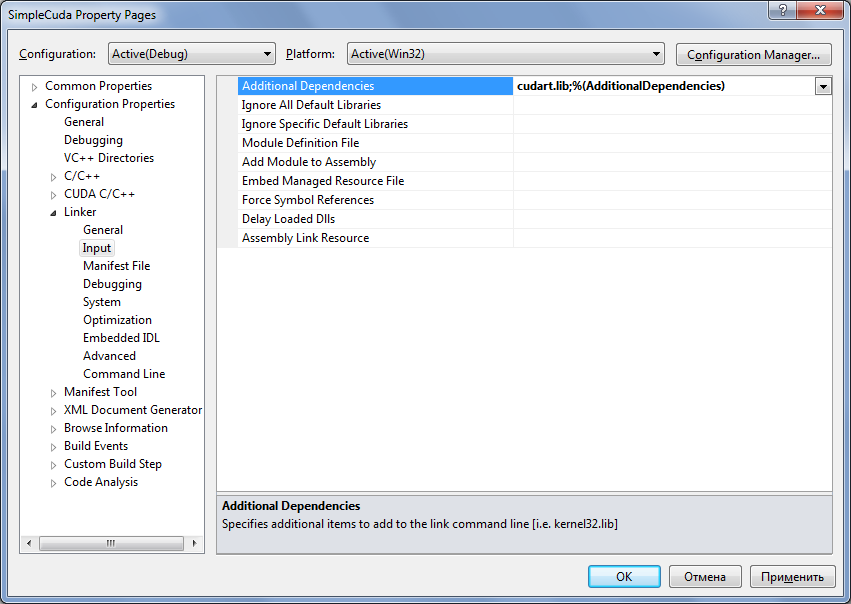
Наконец, на вкладке Linker/Input нужно добавить ссылку на библиотеку CUDA Runtime (cudart.lib).
Для этого в настройку Additional Dependencies добавляется ссылка на соответствующую библиотеку.
Для проверки корректности настроек в файл Program.cu следует добавить пустую реализацию метода
main и скомпилировать проект.
Написание программы
Ниже приведен код простой программы Program.cu, которая увеличивает значение элементов исходного
массива на единицу посредством GPU.
#include <cuda.h>
#include <stdio.h>
__global__ void SomeKernel(int* data, int length)
{
unsigned int threadId = blockIdx.x * blockDim.x
+ threadIdx.x;
if (threadId < length)
{
data[threadId] = data[threadId] + 1;
}
}
void main()
{
int length = 256 * 256;
// Выделение оперативной памяти (для CPU)
int* hostData = (int*)malloc(length * sizeof(int));
// Инициализация исходных данных
for (int i = 0; i < length; ++i)
{
hostData[i] = i;
}
// Выделение памяти GPU
int* deviceData;
cudaMalloc((void**)&deviceData, length * sizeof(int));
// Копирование исходных данных в GPU для обработки
cudaMemcpy(deviceData, hostData, length * sizeof(int),
cudaMemcpyHostToDevice);
dim3 threads = dim3(256);
dim3 blocks = dim3(length / 256);
// Запуск ядра из (length / 256) блоков по 256 потоков,
// предполагая, что length кратно 256
SomeKernel<<<blocks, threads>>>(deviceData, length);
// Считывание результата из GPU
cudaMemcpy(hostData, deviceData, length * sizeof(int),
cudaMemcpyDeviceToHost);
// Отображение результата
for (int i = 0; i < length; ++i)
{
printf("%d\t", hostData[i]);
}
}